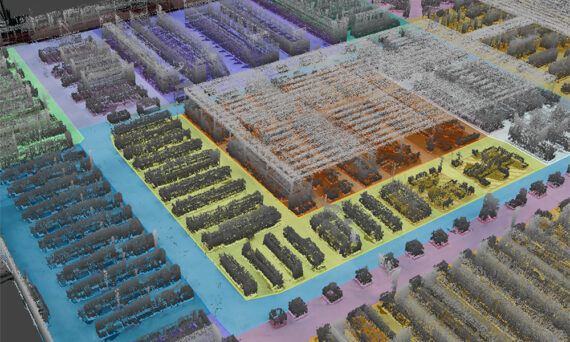
Brain Corp and UC San Diego partner to advance the foundational intelligence layer for physical AI
The research is being led in collaboration with TILOS Robotics team member Dr. Nikolay Atanasov, head of the Existential Robotics Laboratory at the UC San Diego Jacobs School of Engineering, whose work focuses on robotic perception, semantic mapping, and autonomous systems.